Twitter Chess Bot
After creating the chess plotting app covered in a previous article I found myself wanting for a more focussed analysis of individual games. I considered adding this to the functionality of the plotting application but the data and presentation doesn't fit with the structure of the existing features. The application provides summary statistics with a number of optional filters but doesn't have a mode for selecting a single game. It would interfere with the structure of the app to add this and much of the interesting analysis that can be done on a single game requires an engine evaluation.
I could have added another view to the application for single game plots/analysis but I was inspired by F1 Telemetry Bot@F1TelemetryBot to create a bot that could take requests for analysis and return some custom-created graphic. So that is the goal, create a Twitter bot that will listen to or periodically poll a hashtag #chessindata and respond to any new requests with a graphic summarizing the chess game.
Data, Database, and SQLite
One of the largest internet repositories of chess games is Chess.com, where a majority of online games are played. This is the same source of data I used for the chess plotting application so I am able to use many of the same functions but there is a huge hole in the API coverage. There is no sanctioned method to access a single game or even just retrieve summary information(like PGN headers). The inability to access game information using just the game ID would require that the tweet provide at the very least one of the players so that I could search their archieve. However, even this can be prohibitively slow for players that have played over 1000 games so due ot the structure of the API requests I would also require the month that the game was played in. Neither of these options are ideal and greatly increases the chance of an error due to poor 'user' formatting or bad parsing due to the increased complexity of the input.
After scouring the API documentation with no luck I found a forum post that details use of unofficial endpoints to request this data. The risk of these endpoints is that they are only available because Chess.com currently has no mechanism to stop us, so they could go away at any time. However they do work presently and I have had no issues with denied requests.
The endpoint that is useful for me is www.chess.com/callback/live/game/{game_id} whose response headers include the PGN headers of the game in question. This information gives me the date of the game as well as the white and black player usernames so that I can download a single monthly archive and not the entire backcatalog of a player. This is done asynchronously with some tools that I made for my previous chess project.
Database
My previous chess project just processed PGN files into dataframes for each user and saved them as a parquet file for simple archiving. This was useful for the analysis at hand but limits any cross-user analysis or more creative queries. For this project I instead created a SQLite database to store the games and engine evaluations. I created the database as shown in the image below using separate tables for the users, games, moves, and positions. This allows me to query based on the games as I did in this project but it also allows me to query every time a specific move is made(by coordinates or piece) or position is reached, independent of specific game of players. Functionality similar(and much more sophisticated) to this can be seen in the analysis tools of a popular chess database Chessbase.
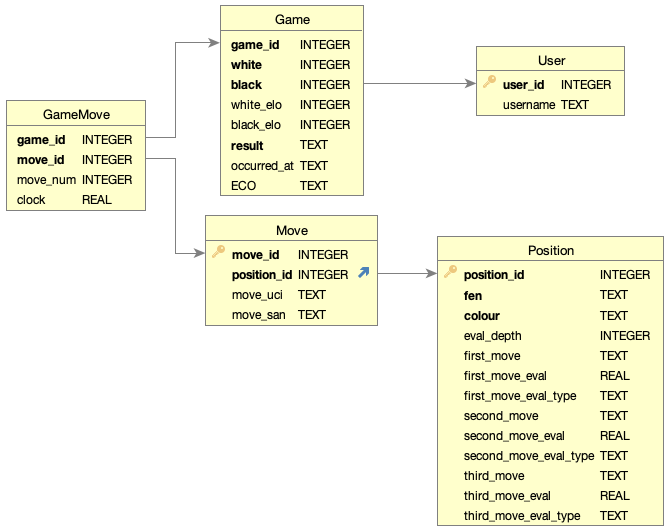
With the exception of the engine evaluation I re-use many of the chess data processing functions from my previous project to ingest the data into the database. To get a proper evaluation of a single game can take a couple of minutes and even just ingesting a single month of games for a single user can turn my computer into a space heater for an hour.
Completing the evaluation independently of ingesting data allows for evaluation on an 'as needed' basis as well as evaluating positions at different depths. This is realized in the final implementation as the bot only retrieves and evaluates positions that haven't already been evaluated at an equal or greater depth. The work done is then saved back to the database for reuse in any other game evaluation. Subsequent requests of the same game will require zero analysis unless a higher engine depth is used.
If I just had free compute sitting around then another option would be to continuously pull unevaluated positions from the database and feed them to the engine. Theoretically once all of the positions were evaluated it could step up the engine depth and go through all of them again.
The main benefit of the positions being stored independently of the games and moves is that positions achieved through transpositions) can be evaluated a single time and used multiple times, eliminating expensive duplicate engine evaluations. This applies to positions achieved through repetitions in a single game or positions reached in different games. This information could be used to evaluate opening positions or popular positions to a greater depth.
A critical component of storing the positions like this is ensuring that they are accurately compared which is more complicated than just inspecting the piece positions. There is also 'metadata' to compare including turn order, castling rights, and en passant. Thankfully these considerations can be accounted for by indexing on a modified FEN which excludes the move numbers. This means that some positions may have all the same pieces in the same positions but result in different entries and evaluations.
Alternatively there is an interesting technique called Zobrist Hashing which uses a large exclusive-or of hashes(one for each piece on each square as well as a small number for move order, castling, etc.) to represent a chess position. A fascinating result of this is moving a piece in the position representation can be done by XORing in the hash for the piece in the current position as well as the piece in the new position. This technique is used for many games/boardgames with a finite number of positions but I decided against it as using the FEN serves another purpose as an input to the chess engine for evaluation.
Engine Evaluations
One of the largest new parts of this project was applying the chess engine to the positions of interest. For this I used the Python library stockfish to access a Stockfish 15.0 instance and it was delightfully simple to have it give it's opinion based on a position reached through a list of moves or directly from a FEN. Despite the ease of setting up an evaluation it takes an exponentially increasing amount of time to evaluate positions as the depth increases. From my testing and some research, a depth of 15-20 is sufficient for any kind of chess below the top levels and there are significant diminishing returns after that.
My first implementation used a single instance of Stockfish but it was quite time consuming to evaluate an entire game so I parallelized it with Python multiprocessing to cut the time down. Entire game evaluations to a depth of 15 can now be done in under a minute. Though it does consume the entire compute bandwidth of my computer for that period. I knew this before but it really highlights why Chess.com charges for their higher evaluation depths.
On a side note I did consider trying to 'piggyback' on the evaluation done by Chess.com but this is not supported by their API and there is no guarantee that the requested game has been evaluated on their website.
Part of the reason that the evaluations are so expensive is that in addition to the evaluation of the position(and the move made in the game) I was requesting the top 3 next moves and their evaluations. This allows me to return the difference in the evaluation of the best move versus the move played. The result is the used for the [centipawn] or [pawn] loss.
Visualization
With the game and evaluation data saved to the database it is all available for visualizations given the right SQL incantations. Though separating out all of the components of the game allows for a lot of flexibility it also requires some verbose SQL queries to join it all back together when requesting data. Despite some of the complexity it does produce more interesting results as some of the queries basically wouldn't be possible if it were all stored in dataframes or the original PGNs.
Below is one of the queries I make to get the counts of move ranks for the white and black players:
SELECT move_rank,
COUNT(CASE move_colour WHEN 'Black' THEN 1 ELSE NULL END) AS Black,
COUNT(CASE move_colour WHEN 'White' THEN 1 ELSE NULL END) AS White
FROM (SELECT gm.move_num,
p.colour,
CASE WHEN p.colour = 'w' THEN 'Black'
WHEN p.colour = 'b' THEN 'White' END AS move_colour,
CASE m.move_uci WHEN LAG(p.first_move, 1) OVER (PARTITION BY g.game_id ORDER BY gm.move_num) THEN 1
WHEN LAG(p.second_move, 1) OVER (PARTITION BY g.game_id ORDER BY gm.move_num) THEN 2
WHEN LAG(p.third_move, 1) OVER (PARTITION BY g.game_id ORDER BY gm.move_num) THEN 3
ELSE 5 END AS move_rank,
m.move_uci,
CASE WHEN p.first_move_eval_type = 'mate' THEN 1000 * (p.first_move_eval)/ABS(p.first_move_eval)
ELSE p.first_move_eval END as eval
FROM Game g
JOIN GameMove gm
ON g.game_id = gm.game_id
JOIN Move m
ON gm.move_id = m.move_id
JOIN Position p
ON m.position_id = p.position_id
WHERE g.game_id = ?
ORDER BY move_num) sub
GROUP BY move_rank
ORDER BY move_rank
The results of the above query along with a number of others is then used along with the plotnine library to generate the plots for the infographic. I have mentioned plotnine before but it is easily my preferred method of plotting with Python. It definitely isn't the easiest or quickest to use for a simple plot but it seems to get easier as the complexity of the plot increases. I have also created a couple personal modules that I use to apply common patterns and this really speeds up the process.
One of the downsides of plotnine is the inability to join plots side-by-side. After searching for a solution for far too long I was able to find patchworklib which enables simple compositions of matplotlib and matplotlib-based plots. This worked brilliantly once I submitted a patch to fix a bug with the patchworklib version compatibility checking.
The resulting composition of the plots can be seen below, it won't win any design awards but I think it gets the point across and it is surpisingly difficult to find a nice background colour when using black and white in the colour scheme.
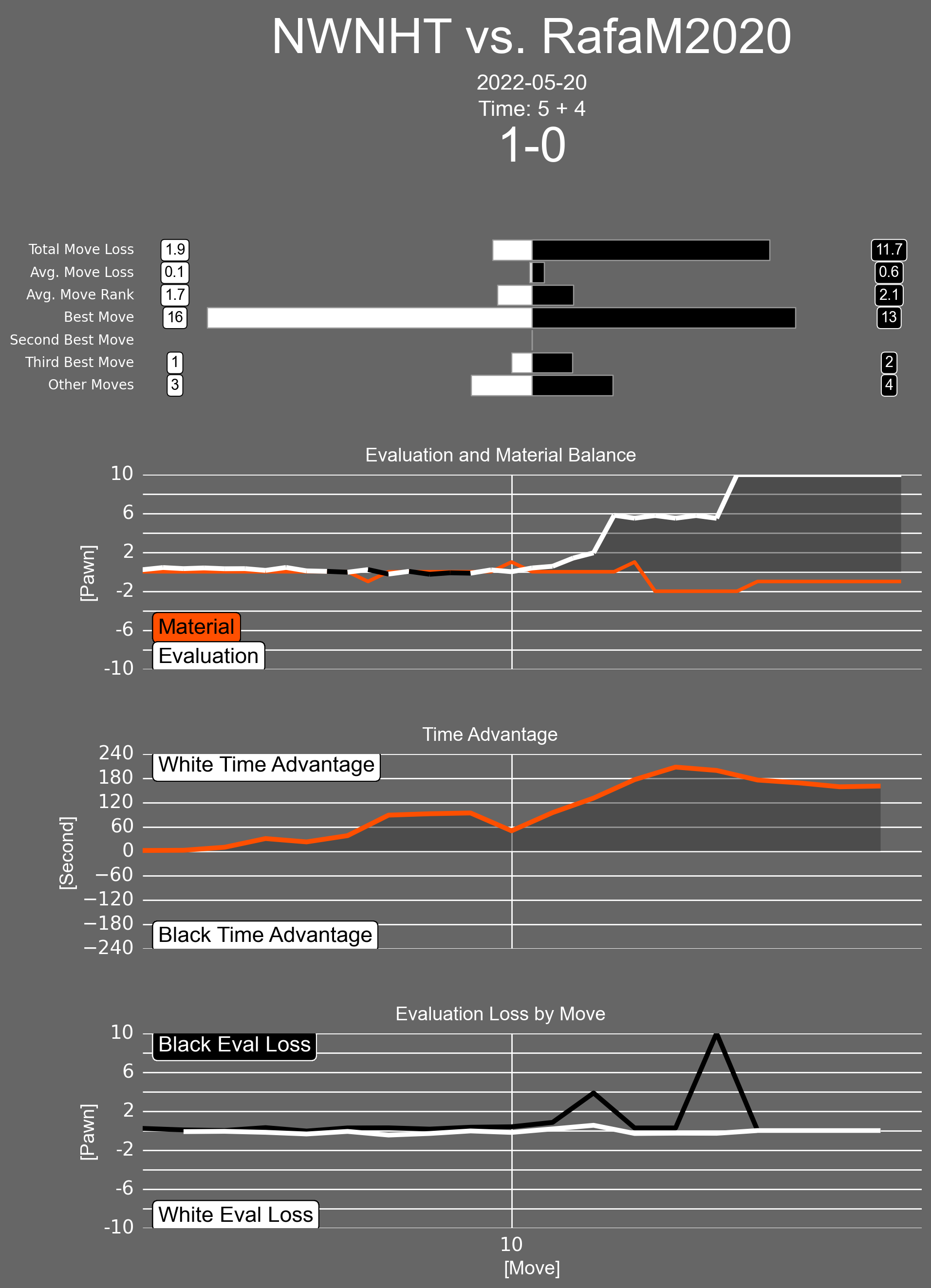
Interpretation
- All evaluations are presented in units of pawns(points of material).
- The "Best Move", "Second Best Move", ... represent the count of total best moves played by each player.
- The Evaluation and Material Balance plot shows the per ply evaluation and material balance.
- The colour of the evaluation plot will change to represent the colour of the side with the advantage.
- The Time Advantage plot shows the time difference from the perspective of the white player.
- The Evaluation Loss by Move plot shows the [pawn] evaluation lost per move, the difference between the evaluation of the best move and the move actually played.
Twitter Integration
- The colour of the evaluation plot will change to represent the colour of the side with the advantage.
For the Twitter integration I decided to use the Tweepy library which comes highly recommended and I can say that it was very straightforward to use to make searches and receive the responses. It provides a few methods to authenticate with the Twitter API and has been extremely reliable.
The Twitter API itself is understandably robust and fully featured though I did have some confusion regarding the multiple versions. I began by using the v2 API as I assumed that it would be best but I soon found that it doesn't include the ability to upload media. This is clearly prohibitive for my purpose so I had to request elevated access and switch to v1.1 API.
I honestly don't have too much else to say about the Twitter integration as it was fairly simple and only required a couple hundred lines, most of which was authentication failsafes.
The backend which downloads, processes, evaluates, and plots the data is completely independent; it takes only a Chess.com game ID as input and outputs the completed image. This means that if somehow Twitter crashes and burns then I should be able to plug this into a Mastodon API or really anything else.
Summary
The result of the above is that when this bot is running, it will find any tweet of the form "chess.com_game_ID #chessindata" and respond within a few minutes with an infographic describing the game. I do have an RPi4 that I could run this on to keep the bot up all of the time but unfortunately I think that a full stockfish evaluation would bring it to it's knees. There are extremely lightweight chess engines that are designed to be run on micro computers but if I am being honest Twitter doesn't need another bot.
This bot is available on Github for the curious.
Since creating this bot there are a few enhancements that I have thought of and might implement if I want to upgrade this in the future. Below are the ones that I have thought of so far but I might add more as Github issues if I have any brilliant ideas.
- Implement ability to choose engine depth in the tweet
- Adjust the time axis labels for the time balance plot depending on time control
- This would make it easier to read for classical time controls but those are rare online
- Get some computer to be continually evaluating positions
- Add some more thoughful or informative text to the tweet instead of just the image, could include some summary statistics or summary